Redis 第一章
Redis 数据结构
Redis 有5种数据结构分别为 STRING(字符串) LIST(列表) SET(集合) HASH(散列) ZSET(有序集合)

STRING
GET 获取存储在给定键中的值
SET 设置存储在给定键中的值
DEL 删除存储在给定键中的值 (这个命令可用于所有类型)
1 | 127.0.0.1:6379> set hello world |
LIST
PRUSH 将给定值推入列表的右端
LRANGE 获取列表在给定范围上的所有值
LINDEX 获取列表在给定位置上的单个元素
LPOP 从列表的左端弹出一个值, 并返回被弹出的值
1 | 127.0.0.1:6379> rpush list-key item |
SET
存储的字符串不是相同的
但是是无序的
SADD 添加到集合
SREM 从集合中去除
smembers
SMEMBERS 获取所有元素(如果元素很多会很慢)
SISMEMBER 快速检测一个元素是否存在集合中
1 | 127.0.0.1:6379> sadd set-key item |
散列
存储多个键值对之间的映射
存储的值即可以是字符串又可以是数字值
HSET 添加
HGET 获取
HGETALL 获取所有
1 | 127.0.0.1:6379> hset hash-key sub-key1 value1 |
ZSET
有序集合和散列一样 都用于存储键值对
有序集合的键被称为成员 (member)
每个成员都是各不相同的
而有序集合的值则被称为分值 (score) 分值必须为浮点数
可以根据分值以及分值的排列顺序来访问元素的结构
ZADD 添加
ZRANGE 获取元素 指定位置
ZRANGEBYSCORE 指定分值条件获取元素
ZREM 删除
1 | 127.0.0.1:6379> zadd zset-key 728 member1 |
这样可以将两个合并到一起来计算 交集的计算 计算的是两个都有的
执行 ZINTERSTORE 命令比较花时间 为了尽量减少redis的工作量 程序将这个命令的计算结果缓存60s
有缓存的话读取缓存 没有的话再重新执行排序并存入缓存
第一章就是这些 这里我们在写个python的代码实例来实现这个网站的点踩功能
实例代码
#!/usr/bin/python
# coding=UTF-8
'''
@Author: recar
@Date: 2019-09-24 19:28:11
@LastEditTime: 2019-09-25 18:03:18
'''
from datetime import datetime
import redis
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
redis_server = "127.0.0.1"
redis_port = 6379
class Article(object):
# 实现一个对于文章点赞点踩的功能
def __init__(self):
self.conn = self.get_connection()
self.zset_article_by_time_key = "article_by_time"
self.zset_article_by_like_key = "article_by_like"
self.hash_article_prefix = "hash_info_article:"
self.set_article_prefix = "set_author_like_article:"
# 分值常量 一天s数/ 需要多少票认为是好的文章
self.constantvalue = 86400 / 10
def get_connection(self):
connect = redis.Redis(host=redis_server, port=redis_port,db=0)
return connect
def add_article(self, article_id, title, author,connect):
# 添加文章
hash_key = self.hash_article_prefix + str(article_id)
self.conn.hset(hash_key, "title", title)
self.conn.hset(hash_key, "author", author)
self.conn.hset(hash_key, "connect", connect)
create_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
time_tuple = time.strptime(create_time, '%Y-%m-%d %H:%M:%S')
timeStamp = time.mktime(time_tuple)
self.conn.hset(hash_key, "create_time", create_time)
# 这里要添加一个文章发布的基于时间的有序集合
self.conn.zadd(self.zset_article_by_time_key, {article_id: timeStamp})
# 创建一个对文章点赞的集合 防止一个人对文章多次点赞
set_key = self.set_article_prefix + str(article_id)
self.conn.sadd(set_key, author)
# 创建一个对文章点赞数的有序集合 用于排序展示 初始都是0
self.conn.zadd(self.zset_article_by_like_key, {article_id: 0})
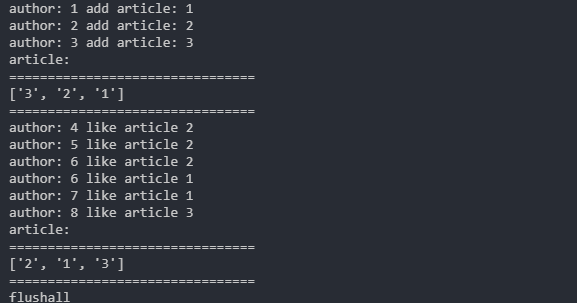
print("author: {0} add article: {1}".format(author, article_id))
def like_article(self, article_id, author):
# 文章被点赞 先判断这个用户是否已经对文章点过赞了
set_key = self.set_article_prefix + str(article_id)
is_exists = self.conn.sismember(set_key, author)
if is_exists:
return
else:
# 将用户添加到集合并
self.conn.sadd(set_key, author)
#对文章有序集合like自增分值
self.conn.zincrby(self.zset_article_by_like_key, self.constantvalue, article_id)
print("author: {0} like article {1}".format(author, article_id))
def get_article_by_like_time(self):
# 获取时间加文章点赞作为分值的排序
self.conn.zinterstore("zset_like_time",
(self.zset_article_by_time_key, self.zset_article_by_like_key),
aggregate="SUM"
)
print("article:")
print("================================")
print(self.conn.zrange("zset_like_time", 0, -1, desc=True))
print("================================")
def clear(self):
for key in self.conn.keys():
self.conn.delete(key)
print("flushall")
def main():
article = Article()
# 添加三篇文章
article.add_article(1,"one",1,"111111111")
article.add_article(2,"two",2,"222222222")
article.add_article(3,"three",3,"3333333")
# 先输出文章
article.get_article_by_like_time()
# 点赞
article.like_article(2,4)
article.like_article(2,5)
article.like_article(2,6)
article.like_article(1,6)
article.like_article(1,7)
article.like_article(3,8)
# 输出文章排序
article.get_article_by_like_time()
article.clear()
if __name__ == "__main__":
main()最后输出