GSIL的分析
对github监控的分析流程
主函数
1 | import sys |
这里要传入规则类型 将gsil函数的返回结果赋值给 exit退出 来抛出异常
否则的话调用 gsil函数
gsil函数
在 init里
1 | def gsil(): |
先看如果参数是 --verify-tokens 开始验证token
实例化 Engine 传入token 调用验证方法 然后log输出
看下engine
verify
1 | def verify(self): |
g是 github实例ret = self.g.rate_limiting
使用的是这个 他返回一个元组 第一个是剩余的可请求数 第二个是请求限制数
所以 我配置了的token是成功了的 默认返回的是 5000次剩余请求和限制数
–report 参数是发送每日运行报告 后面分析
都没有的话 调用 start(sys.argv[1])
1 | # start |
获取规则 从传入的规则类型
哦 这个是你选择规则类型 就是例子中的第一个key
就是第一个test
使用的话就是 python gsil.py test 会解析规则字典后只匹配这个的
配置文件规则
1 | { |
输出规则长度 及定义的规则
开始拼接 key进行搜索
多进程池的形式
多进程调用 search方法pool.apply_async(search, args=(idx, rule_object), callback=store_result)
完成结果调用 store_result
我们看下 search方法
1 | def search(idx, rule): |
search方法
1 | def search(self, rule_object): |
搜索 去重
使用 _exclude_repository 过滤正常的存储库
1 | def _exclude_repository(self): |
搜索
search_code 的keyword是这样的"mogujie.org" extension:php extension:java extension:python extension:go extension:js extension:properties
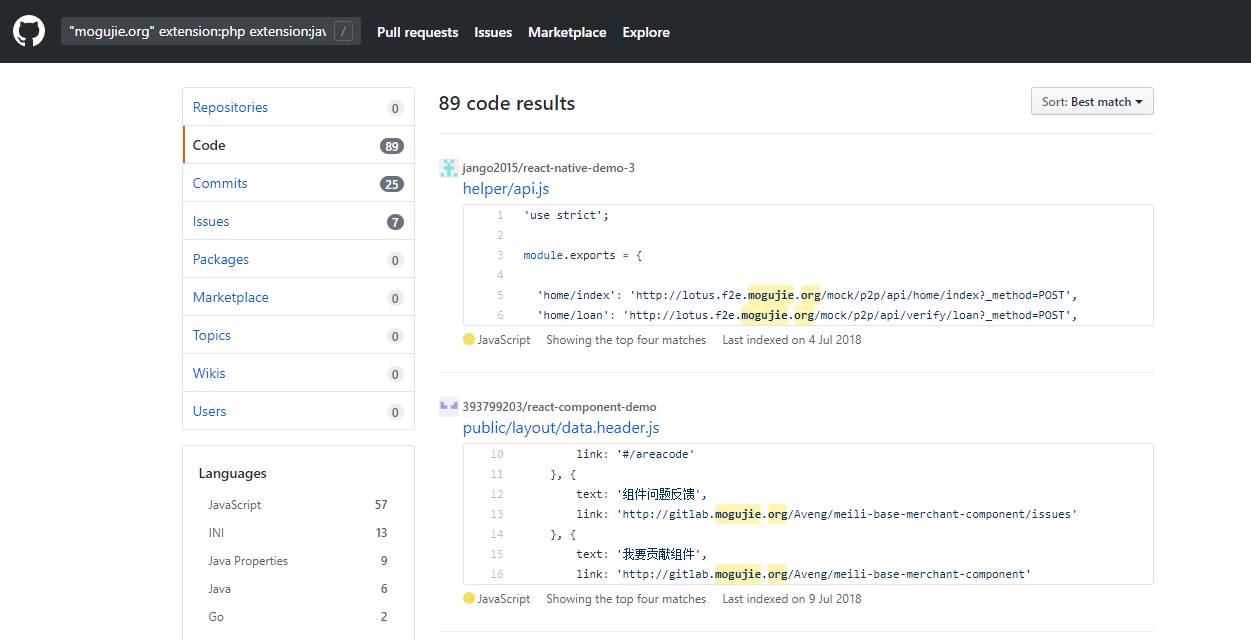
过滤规则
匹配正则 在配置文件config中
路径的过滤
拼接出完整的项目连接'lan1tian/muse/jarvis-web/src/main/resources/development/session.properties'
这是完整的路径
然后 匹配排除规则 正则匹配到排除规则则进行 匹配上返回True 没有匹配上返回 False
1 | exclude_repository_rules = [ |
代码级别的过滤
然后根据配置的规则 的匹配模式 来去获取匹配内容的范围
只匹配命中的那一行 only
匹配命中的上下三行 normal-match
然后再对其进行过滤
1 | exclude_codes_rules = [ |
下面是search后的结果的处理
存储处理的结果
1 | def store_result(result): |
PyGithub
这里根据这个 PyGithub来操作的 https://pygithub.readthedocs.io/en/latest/index.html
可以获取 用户信息 仓库 指定仓库的 start 等等信息
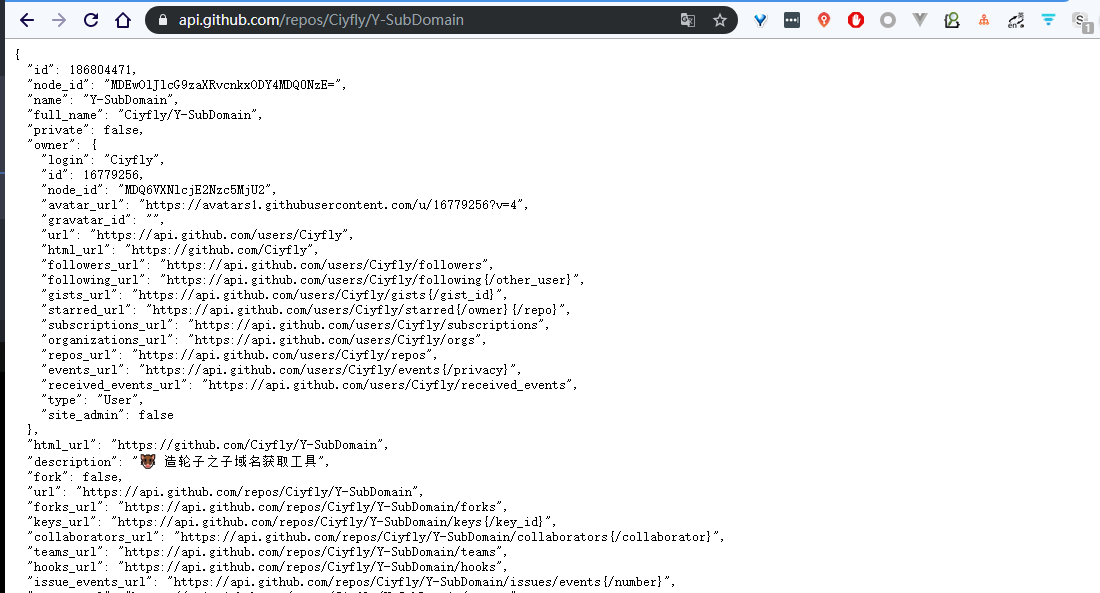
简单的url就是这样的对于一个项目 api
https://api.github.com/repos/Ciyfly/Y-SubDomain
可以返回这个项目的信息的json 直接解析就可以了
整体流程
要先验证token是否能使用
然后根据这个token使用 PyGithub
根据rule.gsil 配置文件加载需要匹配的规则
生成 keyword 比如说域名+ extension:php extension:java extension:python extension:go extension:js extension:properties这样的key 带入去查询获取搜索的结果
使用 PyGithub的 search_code 来获取匹配到的结果
再使用这个对象 进行页面的获取
使用pages_content = resource.get_page(page)`
page是页数 返回匹配的这页的每个对象
然后这个函数 process_pages 处理匹配获取到的
通过路径去过滤 排除文档 博客 爬虫等
再获取匹配的代码 content.decoded_content.decode('utf-8')
content 是匹配的每个项目的搜索对象 可以这样获取匹配的代码 就是图中每个项目方块中的代码
根据配置的规则中写的匹配模式来进行获取代码块
可能是命中的一行或者上下几行的 (同时把图片给去掉也就是 Img标签)
再根据这些代码去过滤 去除 链接 框架等
有问题的话再单独起个进程clone下项目
并且 每一页发送一份报告 多进程的形式去跑多个规则
总体流程就是这样的 试了试效果不是很好 大概是我没有配置好规则 也是现在很多甲方都做了相关的平台进行监控