100 行 xss 检查代码
主方法 scan_page
传入 url 和 data
这里直接看代码
1 | def scan_page(url, data=None): |
这里把匹配与利用的图贴上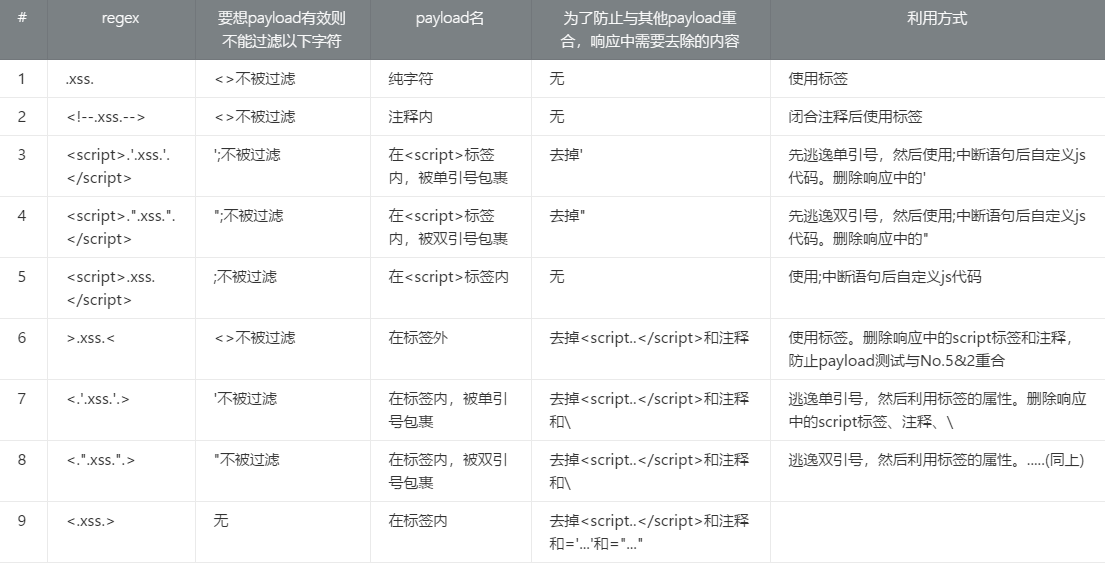
参考 https://www.cnblogs.com/litlife/p/10741864.html#4079918734
100 行 xss 检查代码
主方法 scan_page
传入 url 和 data
这里直接看代码
1 | def scan_page(url, data=None): |
这里把匹配与利用的图贴上
参考 https://www.cnblogs.com/litlife/p/10741864.html#4079918734