pyton排除celery两种常见的任务队列
rq
count_words_at_url work需要执行的函数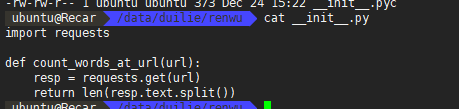
rq_test.py
1 | #!/usr/bin/python |
设置环境变量 让work能找到 count_words_at_url函数export PYTHONPATH=/当前路径/:$PYTHONPATH
启动work
在 work函数目录下 rq worker --with-scheduler
成功执行
启动两个work试试
rq info 可以看到work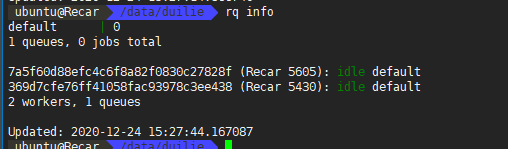
执行
可以看到两个work都执行了
支持重试
1 | from rq import Retry |
定时任务
1 | # Schedule job to run at 9:15, October 10th |
深入
队列初始化
队列初始化的时候可以设置name等参数
rq/queue.py:59
1 | def __init__(self, name='default', default_timeout=None, connection=None, |
入队
函数,参数queue.enqueue('renwu.count_words_at_url', 'http://nvie.com')
1 | def enqueue(self, f, *args, **kwargs): |
1 | timeout 用于指定作业被中断并标记为失败之前的最大运行时间。默认单位是秒,可以是整数或表示整数的字符串 ( 例如,2,'2') 。此外,还可以是具有指定单位的字符串,包括小时,分钟,秒(例如'1h','3m','5s') |
我们也可以直接使用 enqueue_call函数来创建更复杂的队列
返回回来的队列实例q也有很多使用方法
1 | ['DEFAULT_TIMEOUT', '__bool__', '__class__', '__delattr__', '__dict__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_default_timeout', '_is_async', '_key', 'acquire_cleaning_lock', 'all', 'compact', 'connection', 'count', 'create_job', 'deferred_job_registry', 'delete', 'dequeue_any', 'empty', 'enqueue', 'enqueue_at', 'enqueue_call', 'enqueue_dependents', 'enqueue_in', 'enqueue_job', 'failed_job_registry', 'fetch_job', 'finished_job_registry', 'from_queue_key', 'get_job_ids', 'get_jobs', 'is_async', 'is_empty', 'job_class', 'job_ids', 'jobs', 'key', 'lpop', 'name', 'parse_args', 'pop_job_id', 'push_job_id', 'redis_queue_namespace_prefix', 'redis_queues_keys', 'registry_cleaning_key', 'remove', 'run_job', 'scheduled_job_registry', 'started_job_registry'] |
获取队列长度 len(queue)
获取所有id为 xxx的job job = queue.fetch_job(xxx)
回去返回结果 使用装饰器
job.result 没有执行完会返回空 否则会返回结果
执行函数 在renwu目录下
1 | from rq.decorators import job |
测试调用函数
1 | from renwu import add |
work执行 (在跟 执行函数一个目录下)rq worker low
python test.py

这里 创建队列的时候指定了 name是 low 所以 work使用的时候也是要指定low队列
work 可以-u指定redis连接
huey
使用
目录
1 | ├── task.py |
task.py
1 | from huey import RedisHuey, crontab |
test.py
1 | from task import add_numbers |
work
先设置环境变量 export PYTHONPATH=/当前路径/:$PYTHONPATH
在当前目录下执行 huey_consumer.py task.huey
后面的参数是 创建的队列的路径
还可指定work数量 -k process -w 4
并且可以指定 协程 进程等
执行
文档
https://huey.readthedocs.io/en/latest/
demo https://github.com/coleifer/huey/tree/master/example
比较
相比较 celery 是比较笨重 但是应用广泛 经常出现不消费任务的情况
今天了解的这两个消费队列 相对轻便 具体消费情况还没有测试
huey 文档全面
rq的issues更活跃 (star 7.4k)
huey没有issues (3.3k)
个人倾向于 huey 后面在实际使用中看下效果吧
参考
https://www.twle.cn/t/39
https://huey.readthedocs.io/en/latest/
https://github.com/coleifer/huey/tree/master/examples
https://github.com/rq/rq